Embodied-R1.5 is a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities — spanning embodied cognition, task planning, correction, and pointing — within a single 8B-parameter architecture toward general physical intelligence. It achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing Gemini-Robotics-ER-1.5 and GPT-5.4, and can be fine-tuned into a VLA that outperforms π₀.₅ across 4 popular manipulation benchmark suites.
Unified Embodied Foundation Model
We formalize the capability requirements of an EFM and demonstrate that embodied cognition, task planning and correction, and pointing and location can coexist and reinforce each other within a single 8B-parameter architecture, eliminating the fragmented multi-model paradigm.
Large-Scale Data System & Multi-Task Balanced RL
Leveraging three automated data construction pipelines, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe with output-type-specific rewards that resolves interference inherent in heterogeneous multi-task training.
Planner-Grounder-Corrector Closed-Loop Framework
A Planner-Grounder-Corrector (PGC) closed-loop framework where a single model orchestrates the full autonomy stack — from high-level task decomposition and precise spatial grounding to autonomous self-correction over long-horizon tasks.
SOTA Results & Full Open-Source Ecosystem
Achieves SOTA on 16/24 embodied VLM benchmarks, surpassing Gemini-Robotics-ER-1.5 and GPT-5.4. Fine-tuned as a VLA, it outperforms π₀.₅ across 4 manipulation benchmark suites. We fully open-source model weights, datasets, training code, and EmbodiedEvalKit.
Per-benchmark scores across all evaluated tasks.
Embodied-R1.5-VLA is built upon Embodied-R1.5 as the backbone, augmented with an action head for VLA training — without large-scale action pretraining. We demonstrate that broad improvements in embodied capabilities effectively transfer to downstream VLA manipulation performance.
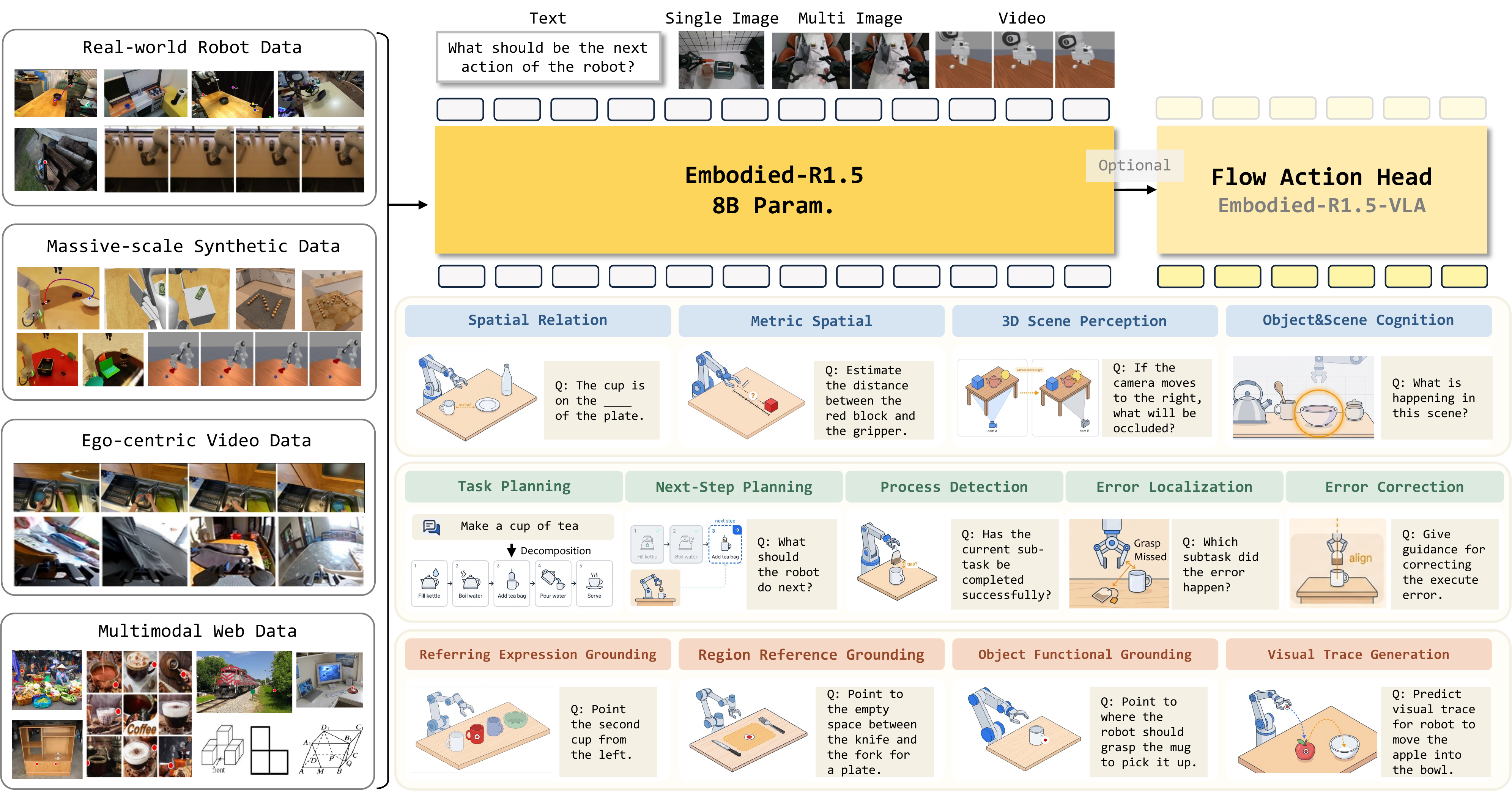
Embodied-R1.5 integrates Planner, Grounder, and Corrector into a unified closed-loop pipeline, where a single model orchestrates the full autonomy stack — from high-level task decomposition and precise spatial grounding to autonomous reflection and self-correction. This enables complex, long-horizon embodied tasks across diverse robotic embodiments without human intervention.
Compared with its predecessor, Embodied-R1.5 features comprehensive advancements in cognition, planning, and error correction, while significantly refining its pointing and localization precision. It currently establishes a new SOTA across 10+ benchmarks, with its mean performance markedly exceeding that of leading general-purpose and embodied models. Notably, Embodied-R1.5 demonstrates a clear competitive advantage over Gemini-Robotics-ER-1.5 across all evaluated capability domains.
Comprehensive evaluation across Embodied Planning and Correction (4 Tasks), Embodied Pointing and Location (9 Tasks), and Embodied Cognition and Spatial Reasoning (8 Tasks).
Visual trace prediction evaluation across ShareRobot-V (RMSE↓, DFD↓), VABench-V (RMSE↓, DFD↓), and PIO-S3 (GPT-Score↑).
Embodied-R1.5 maintains strong general vision capabilities while acquiring comprehensive embodied skills, demonstrating minimal performance trade-off compared to its base model Qwen3-VL-8B.
Demonstrating superior generalization performance, Embodied-R1.5-VLA excels in all three Simpler evaluation suites. In the rigorous Google Robot Benchmark, our model outperforms the leading baseline, pi0, by a substantial 20% margin, setting a new performance standard for embodied agents.
| Model | Pick Coke Can | Move Near | Open/Close Drawer | Open Top Drawer & Place Apple |
Overall |
|---|---|---|---|---|---|
| RT-1-X | 56.7 | 31.7 | 59.7 | 21.3 | 42.4 |
| RT-2-X | 78.7 | 77.9 | 25.0 | 3.7 | 46.3 |
| OpenVLA | 16.3 | 46.2 | 35.6 | 0.0 | 24.5 |
| SpatialVLA | 86.0 | 77.9 | 57.4 | 0.0 | 55.3 |
| pi0 | 97.9 | 78.7 | 62.3 | 46.6 | 71.4 |
| pi0-FAST | 75.3 | 67.5 | 42.9 | 0.0 | 46.4 |
| GR00T N1.5 | 51.7 | 54.0 | 27.8 | 7.4 | 35.2 |
| Embodied-R1.5-VLA | 92.3 | 93.8 | 86.1 | 97.2 | 92.4 |
| Model | Pick Coke Can | Move Near | Open/Close Drawer | Open Top Drawer & Place Apple |
Overall |
|---|---|---|---|---|---|
| RT-1-X | 49.0 | 32.3 | 29.4 | 10.1 | 30.2 |
| RT-2-X | 82.3 | 79.2 | 35.3 | 20.6 | 54.4 |
| OpenVLA | 54.5 | 47.7 | 17.7 | 0.0 | 30.0 |
| SpatialVLA | 88.0 | 72.7 | 41.8 | 6.3 | 52.2 |
| pi0 | 90.1 | 80.7 | 27.6 | 20.5 | 54.7 |
| pi0-FAST | 77.6 | 68.2 | 31.3 | 0.0 | 44.3 |
| GR00T N1.5 | 69.3 | 68.7 | 35.8 | 4.0 | 44.5 |
| Embodied-R1.5-VLA | 80.6 | 72.2 | 58.3 | 75.0 | 71.5 |
| Model | Put Spoon on Towel |
Put Carrot on Plate |
Stack Blocks | Put Eggplant in Basket |
Overall |
|---|---|---|---|---|---|
| RT-1-X | 0.0 | 4.2 | 0.0 | 0.0 | 1.1 |
| CogACT | 71.7 | 50.8 | 15.0 | 67.5 | 51.3 |
| OpenVLA | 4.2 | 0.0 | 0.0 | 12.5 | 4.2 |
| SpatialVLA | 16.7 | 25.0 | 29.2 | 100.0 | 42.7 |
| pi0 | 29.1 | 0.0 | 16.6 | 62.5 | 27.1 |
| pi0-FAST | 29.1 | 21.9 | 10.8 | 66.6 | 32.1 |
| GR00T N1.5 | 75.3 | 54.3 | 57.0 | 61.3 | 62.0 |
| Embodied-R1.5-VLA | 83.3 | 75.0 | 37.5 | 100.0 | 74.0 |
Efficient VLM-to-VLA Adaptation: Embodied-R1.5-VLA achieves high-performance control via direct fine-tuning from a VLM, successfully bypassing the conventional requirement for massive real-robot action pre-training.
Top-Tier Benchmark Dominance: The model demonstrates comprehensive task mastery across all LIBERO suites, reaching first-tier performance and significantly outperforming existing methods that lack action pre-training.
Superior Architectural Stability: Compared to native backbones like Qwen3-VL, Embodied-R1.5 delivers consistent and stable performance gains throughout the entire training curriculum.
| Model | Pt. | Goal | Spatial | Object | Long | Overall |
|---|---|---|---|---|---|---|
| W/ Action Pretraining | ||||||
| SpatialVLA | Y | 78.6 | 88.2 | 89.9 | 55.5 | 78.1 |
| CoT-VLA | Y | 87.6 | 87.5 | 91.6 | 69.0 | 83.9 |
| GR00T N1 | Y | 93.0 | 94.4 | 97.6 | 90.6 | 93.9 |
| GR00T N1.6 | Y | 97.5 | 97.7 | 98.5 | 94.4 | 97.0 |
| OpenVLA | Y | 79.2 | 84.7 | 88.4 | 53.7 | 76.5 |
| OpenVLA-OFT | Y | 97.9 | 97.6 | 98.4 | 94.5 | 97.1 |
| pi0 | Y | 95.8 | 96.8 | 98.8 | 85.2 | 94.2 |
| pi0-FAST | Y | 88.6 | 96.4 | 96.8 | 60.2 | 85.5 |
| pi0.5 | Y | 98.0 | 98.8 | 98.2 | 92.4 | 96.9 |
| W/O Action Pretraining | ||||||
| Diffusion Policy | N | 68.3 | 78.3 | 92.5 | 50.5 | 72.4 |
| OpenVLA-OFT | N | 91.7 | 94.3 | 95.2 | 86.5 | 91.9 |
| pi0-FAST | N | 89.0 | 87.0 | 63.0 | 48.0 | 71.8 |
| pi0.5 | N | 94.6 | 96.6 | 97.2 | 85.8 | 93.6 |
| Embodied-R1.5-VLA | N | 97.4 | 97.8 | 99.2 | 93.2 | 97.3 |
Evaluating model robustness across 7 perturbation types: Camera, Robot, Language, Light, Background, Noise, and Layout changes.
Overall success rates across training steps with different VLM backbones and action experts.
| Model | Seen Categories | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Safe |
Door |
Display |
Fridge |
Laptop |
Lighter |
Micro. |
Mouse |
Box |
Trash |
Pot |
Suitcase |
Pliers |
Storage |
Remote |
|
| Where2Act | 0.26 | 0.36 | 0.19 | 0.27 | 0.23 | 0.11 | 0.15 | 0.47 | 0.14 | 0.24 | 0.13 | 0.12 | 0.56 | 0.68 | 0.07 |
| FlowBot3D | 0.67 | 0.55 | 0.20 | 0.32 | 0.27 | 0.31 | 0.61 | 0.68 | 0.15 | 0.28 | 0.36 | 0.18 | 0.21 | 0.70 | 0.18 |
| Implicit3D | 0.53 | 0.58 | 0.35 | 0.55 | 0.28 | 0.66 | 0.58 | 0.51 | 0.52 | 0.57 | 0.45 | 0.34 | 0.41 | 0.54 | 0.39 |
| ManipLLM | 0.68 | 0.64 | 0.36 | 0.77 | 0.43 | 0.62 | 0.65 | 0.61 | 0.65 | 0.52 | 0.53 | 0.40 | 0.64 | 0.71 | 0.60 |
| Embodied-R1.5 | 0.96 | 0.92 | 0.92 | 0.88 | 0.90 | 0.80 | 0.96 | 0.59 | 0.94 | 0.33 | 1.00 | 0.50 | 0.28 | 1.00 | 0.58 |
| Model | Seen (cont.) | AVG (Seen) |
Unseen Categories | AVG (Unseen) |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Bottle |
Chair |
Toaster |
Lamp |
Disp. |
Toilet |
Scissors |
Table |
Stapler |
Kettle |
USB |
Washer |
Oven |
Faucet |
Phone |
|||
| Where2Act | 0.40 | 0.13 | 0.18 | 0.13 | 0.40 | 0.26 | 0.18 | 0.35 | 0.38 | 0.28 | 0.05 | 0.21 | 0.17 | 0.20 | 0.15 | 0.15 | 0.21 |
| FlowBot3D | 0.26 | 0.17 | 0.53 | 0.29 | 0.42 | 0.37 | 0.23 | 0.10 | 0.60 | 0.39 | 0.27 | 0.42 | 0.28 | 0.51 | 0.13 | 0.23 | 0.32 |
| Implicit3D | 0.43 | 0.27 | 0.65 | 0.20 | 0.33 | 0.46 | 0.45 | 0.17 | 0.80 | 0.53 | 0.15 | 0.69 | 0.41 | 0.31 | 0.30 | 0.31 | 0.41 |
| ManipLLM | 0.64 | 0.41 | 0.75 | 0.44 | 0.67 | 0.59 | 0.38 | 0.22 | 0.81 | 0.86 | 0.38 | 0.85 | 0.42 | 0.83 | 0.26 | 0.38 | 0.54 |
| Embodied-R1.5 | 0.62 | 0.82 | 0.68 | 0.47 | 1.00 | 0.76 | 0.67 | 0.25 | 0.73 | 0.76 | 0.94 | 0.22 | 0.90 | 0.92 | 0.69 | 0.53 | 0.66 |
Embodied-R1.5 predicts interaction affordances across 30 object categories in ManiSkill PartNet-Mobility.
Embodied-R1.5 demonstrates strong real-world manipulation capabilities across 5 diverse tasks, significantly outperforming prior models in both tool affordance understanding and complex multi-step reasoning.
Pick up [X] and put it on the plate
(Pick&Place)
Put the third duck toy from the left on the plate
(Spatial Reasoning)
Door Open
(Articulated Object Manipulation)
Move [X] to the empty space on the right side of the table
(Tool Affordance) #1
Move [X] to the empty space on the right side of the table
(Tool Affordance) #2
Move [X] to the empty space on the right side of the table
(Tool Affordance) #3
Clean the vase
Open the Drawer
Plug the charger into the socket
Put all the clutter on the table into the box
Put the specified object into the empty space of the table
Stack the cups into three layers
Sweep the garbage on the ground into the dustpan
Make the milk tea
Take out the blue cup and place it on the coaster
A unified evaluation framework for assessing MLLM on embodied intelligence tasks. View on GitHub →
Multiple Inference Backends
vLLM (tensor parallel & multi-GPU), HuggingFace Transformers, and API — switch backends in one config.
20+ Models Supported
GPT, Gemini, Qwen, InternVL, Molmo, Magma and more — generalist and embodied-specialist families out of the box.
20+ Embodied Benchmarks
Embodied QA, Spatial Reasoning, Embodied Pointing, Affordance and Location, and Embodied Planning — all in one place.
Standardized Dataset Format
All benchmarks reorganized into HuggingFace Parquet — unified data pipeline for reproducible evaluation.
Unified Pointing Evaluation
One interface for diverse pointing formats, coordinate systems, and model-specific conventions.
Modular & Decoupled Design
Models, benchmarks, and metrics cleanly separated — easy to extend, swap, or customize independently.
Yifu Yuan proposed the methodology and research direction, developed the complete training dataset, and was responsible for the entire pipeline, including algorithm implementation, model training, inference, and experimental analysis. Yifu Yuan also led the design of the EmbodiedEvalKit framework for evaluation and the drafting of the manuscript.
Yifu Yuan, Hongyao Tang, and Yi Ma served as co-project leads, overseeing the overall execution of the project. The corresponding authors are Shuyang Gu, Yi Ma, Hongyao Tang, and Jianye Hao.
The success of the Embodied-R1.5 project is a collective effort of all contributors. Yaoting Huang, Linqi Han, and Jiangeng Sun contributed to model evaluation. Data construction and cleaning were performed by Yaoting Huang, Linqi Han, Pengyi Li, Jiangeng Sun, Wenting Jia, Yucheng Hu, Zhao Zhang, and Yuxiao Li. The real-world robotic platform setup and experiments were conducted by Shuoheng Zhang, Xianze Yao, Pengyi Li, Yuhao Liu, Yutong Li, Ruihao Liao, Qiyu Wu, and Yuxiao Li. Research guidance and supervision were provided by Shuyang Gu, Zibin Dong, Fei Ni, Yan Zheng, Han Hu, and Jianye Hao.
@article{yuan2026embodiedr15,
title={Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models},
author={Yuan, Yifu and Huang, Yaoting and Yao, Xianze and Li, Yutong and Zhang, Shuoheng and Han, Linqi and Li, Pengyi and Sun, Jiangeng and Jia, Wenting and Zhang, Zhao and Liu, Yuhao and Liao, Ruihao and Hu, Yucheng and Wu, Qiyu and Li, Yuxiao and Dong, Zibin and Ni, Fei and Zheng, Yan and Gu, Shuyang and Ma, Yi and Tang, Hongyao and Hu, Han and Hao, Jianye},
journal={arXiv preprint},
year={2026}
}@article{yuan2025embodied,
title={Embodied-R1: Reinforced Embodied Reasoning for General Robotic Manipulation},
author={Yuan, Yifu and Cui, Haiqin and Huang, Yaoting and Chen, Yibin and Ni, Fei and Dong, Zibin and Li, Pengyi and Zheng, Yan and Hao, Jianye},
journal={ICLR 2026},
year={2025}
}@article{yuan2025seeing,
title={From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation},
author={Yuan, Yifu and Cui, Haiqin and Chen, Yibin and Dong, Zibin and Ni, Fei and Kou, Longxin and Liu, Jinyi and Li, Pengyi and Zheng, Yan and Hao, Jianye},
journal={ICLR 2026},
year={2025}
}